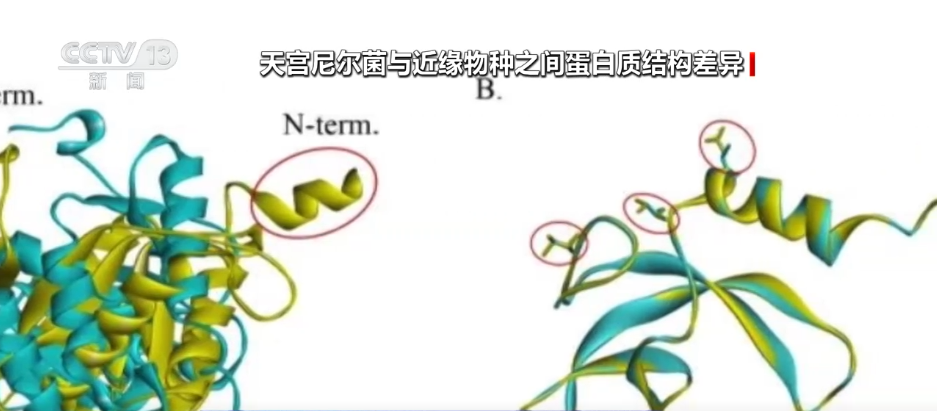
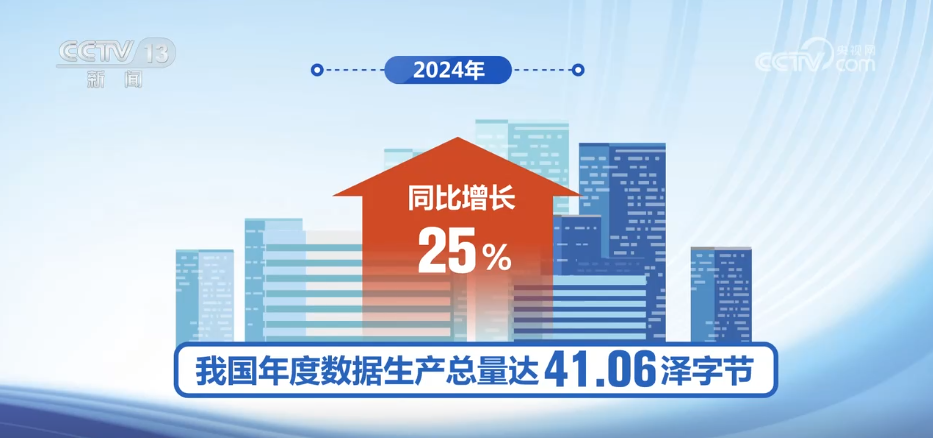
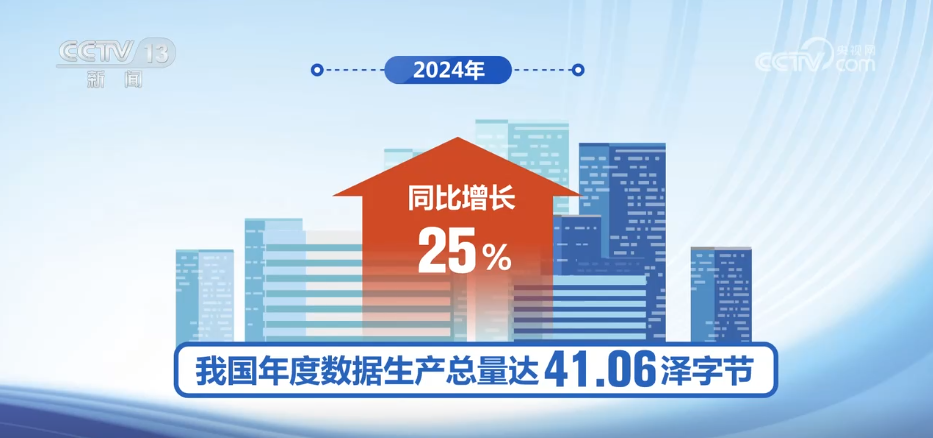
CCTVニュース:5月17日、記者は2025年のデータセキュリティ開発会議から、私の国がデータファクター業界チェーンの多くの上流および下流の企業を育成し、拡大することを学びました。 2030年までに、私の国のデータ産業の規模は7.5兆元に達すると推定されています。
 >
>
Liu Liehong氏は、現在、水平、垂直、および強力なデータインフラストラクチャシステムを構築し、基本的に2029年までに国家データインフラストラクチャの主要構造を構築することを計画していると述べました。 src = "http://www.china-news-online.com/pic/2025-05-18/1kqbamcvbsw.png" alt = "" //
公開データのオープン共有は、データ要素の市場で重要なブレークスルーとなっています。 2024年には、全国の地方自治体レベル以上の地元のパブリックデータのオープンプラットフォームの数が7.5%増加し、オープンデータの数が7.1%増加し、高品質のデータセットの数が前年比27.4%増加しました。データ要素と産業の統合に関しては、国は公開データ共有に対するオープニングアップバリアを加速し、パブリックデータとエンタープライズデータの深い統合を促進し、大規模な「睡眠データ」をアクティブ化しています。
人工知能の開発を加速するための高品質のデータセットの構築
現在、データは従来の生産要因を超えており、人工知能技術と産業変換のブレークスルーの核となる原動力となっています。高品質のデータセットは、人工知能モデルのパフォーマンスの飛躍の基礎であるだけでなく、工業チェーン全体を技術研究開発から商業的実装に変えます。では、高品質のデータセットはどのように構築されていますか?

技術者は記者団に、大規模なモデルデータセットの構築には、主にデータ収集、データクリーニング、データ注釈、品質評価などのコアリンクが含まれていると語った。各リンクは、業界の大規模で十分な多様性、および強力な垂直属性の特性に基づいて、ターゲットを絞った技術研究開発と適応を実行する必要があります。
データアノテーションとクリーニングは、高品質のデータセットの構築における重要なリンクです。データアノテーションは、人工知能を「ラベル付け」(写真の「猫」や「犬」のラベル付けなど)で「世界を認識する」ことを教えています。非標識データは、文字化けした教科書のようなものであり、人工知能が効果的に学習できないことになります。データクリーニングは、複製を削除してエラーを修正することによりデータを浄化し、カオスデータは人工知能トレーニングの有効性に直接影響します。
私の国のデータラベル付け業界の出力値は80億を超えています
データラベル付けは、高品質のデータセットの構築における重要なリンクであることがわかります。それで、私の国の関連産業の発展は何ですか? 2025データセキュリティ開発会議によって発表された「2025高品質のデータセット調査レポート」は、人工知能と大規模なモデル技術の反復により、私の国のデータラベル付け業界の出力値が80億元を超え、高品質のデータの建設が大規模および標準化された開発の新しい段階に入ったことを示しています。
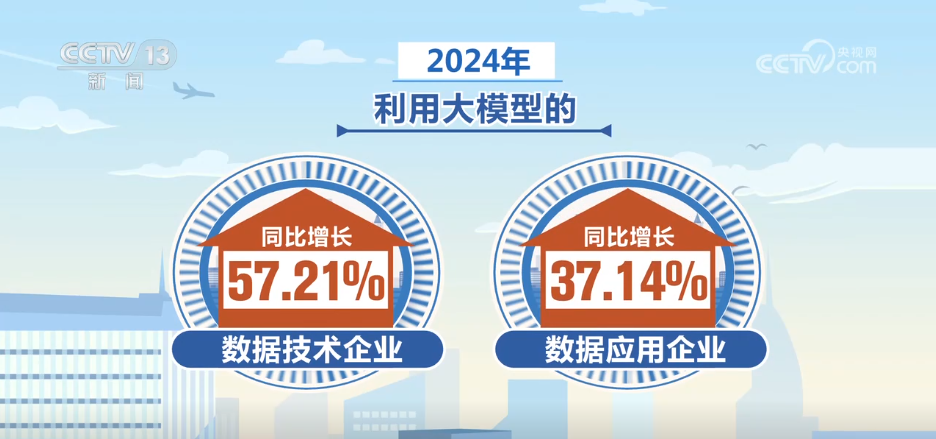

小規模データストック、生産量の少ない、データセットの不均一な品質、主流の高価値データガイダンスの欠如、データ利用効率が低いなどの問題に直面しています。
<! - repaste.body.end->